Data capture : introduction
Fonctionnalités & objectifs
Introduction
Ce document présente l’ensemble des informations relatives aux fonctionnalités du module Data Capture, en particulier celles concernant l’intégration de fichiers structurés au sein de la plateforme Axelor Open Suite (formats pris en charge : JSON, Factur-X, EDIFACT, etc.).
La présente documentation se fonde sur la version 8.3 du module Data Capture, à partir de laquelle elle a été élaborée.
Consultez sur les images suivantes les versions de Data Capture et la compatibilité.
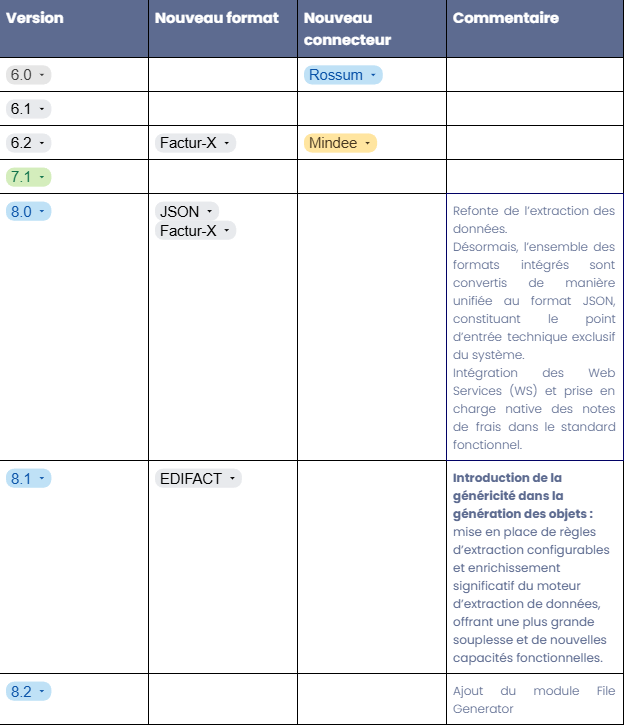
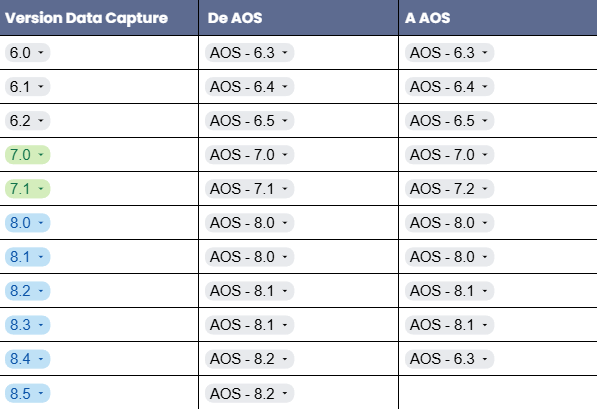
Présentation générale
Data Capture est un module conçu pour permettre l’intégration et le traitement automatisé de fichiers structurés dans l’écosystème Axelor Open Suite (AOS). Il facilite la gestion, l’interprétation et la transformation de documents au format JSON, EDI, Factur-X, PDF, ou encore image, afin de les exploiter directement dans AOS ou au sein d'autres systèmes connectés.
Contexte réglementaire
Dans le cadre de la réforme de la facturation électronique, dont l’entrée en vigueur est prévue pour 2026, les entreprises devront adopter des formats de factures standardisés et favoriser la structuration des échanges dématérialisés.
Axelor s’inscrit dans cette dynamique en développant les modules Data Capture et File Generator, deux outils complémentaires conçus pour assurer l’intégration bidirectionnelle des données entre AOS et des fichiers externes.
Facturation électronique
Une facture électronique se définit comme un document répondant à un format normé, facilitant son traitement automatique par les systèmes d'information. Parmi les formats les plus couramment utilisés, on retrouve Factur-X et UBL.
Le module Data Capture permet notamment d’automatiser la lecture, l’extraction et l’intégration des données issues de ces documents.
Prise en charge de l’EDI
Le module prend également en charge les fichiers EDI (Échange de Données Informatisé), un standard utilisé pour les échanges électroniques entre entreprises, notamment pour les factures, bons de commande, ou autres documents commerciaux. Les formats pris en charge incluent notamment EDIFACT, CII et UBL.
Détail des formats supportés
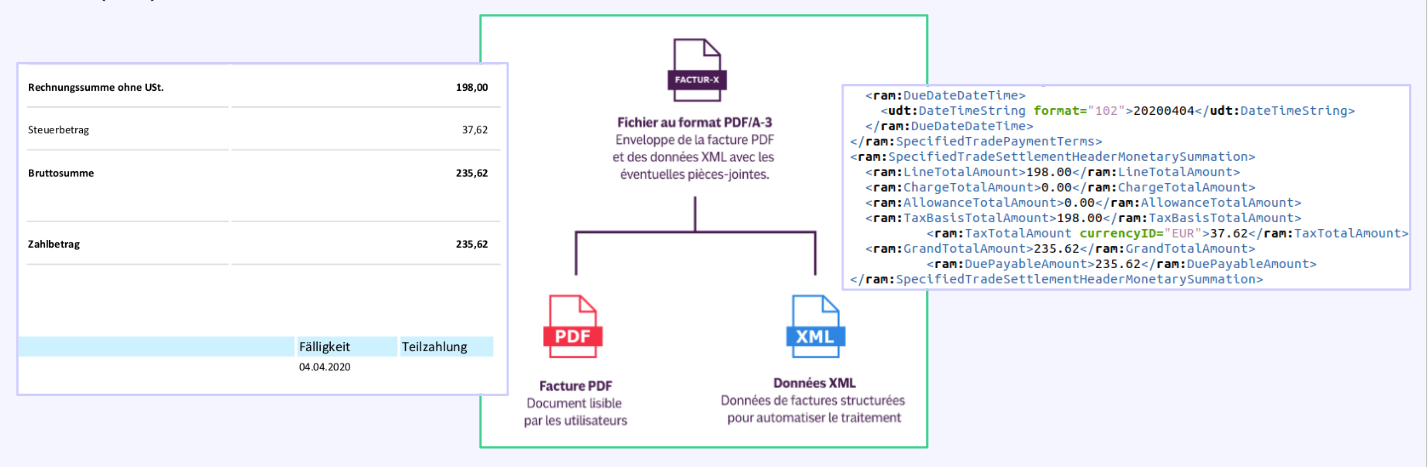
- Factur-X: le format Factur-X repose sur un modèle hybride.
-
Un fichier PDF lisible par l’humain.
-
Un fichier XML structuré, contenant les données de facturation intégrables automatiquement.
Ce double format garantit à la fois la conformité réglementaire, la facilité de lecture, et l’automatisation du traitement.
- EDIFACT: un fichier EDIFACT est structuré selon une logique hiérarchique.
-
Il est lu ligne par ligne, chaque ligne représentant un segment.
-
Chaque segment est composé de composites et d’éléments.
-
Certains éléments peuvent utiliser une code-list (liste codifiée de valeurs autorisées), facilitant la normalisation.Les code-lists sont des enum qui représentent toutes les valeurs possibles de cet élément.
-
Si aucune code-liste n’est utilisée, la valeur est directement extraite telle quelle.

- Ainsi, un exemple de ligne qui peut être lue dans un Edifact (voir l'image 1.3 ci-dessus)

-
Ici, le nom du segment est donc “BGM”.
-
Le caractère ‘ indique la fin du segment.
-
Chaque + représente un passage à un objet suivant, et chaque : indique un passage à un objet interne.
-
Les valeurs représentent les informations suivantes :
BGM BEGINNING OF MESSAGE Function : a segment by which the sender must uniquely identify the document
C002 DOCUMENT NAME 1001 Document name, coded 1131 Code list qualifier 3055 Code list responsible agency, coded 1000 Document name 1004 DOCUMENT NUMBER 1225 MESSAGE FUNCTION 4343 RESPONSE TYPE
Ainsi l’exemple ci-dessus serait représenté en JSON comme ceci :

Connexion aux plateformes OCR
Afin de permettre le traitement de documents non structurés, tels que des images ou des fichiers PDF, le module Data Capture offre une connexion native avec des plateformes de reconnaissance optique de caractères (OCR). Ces plateformes analysent les documents transmis, en extraient les données pertinentes, puis les convertissent en un format JSON directement exploitable par Data Capture.
À ce jour, deux solutions OCR sont prises en charge : Mindee et Rossum. L’utilisation de ces services nécessite la création d’un compte auprès du fournisseur concerné.
Objectifs et fonctionnalités clés
Le module Data Capture a été conçu pour répondre aux besoins d’automatisation, de fiabilité et de flexibilité dans l’intégration de données. Il se distingue par les fonctionnalités suivantes :
-
Automatisation de l’intégration documentaire: suppression des saisies manuelles grâce à un moteur d’extraction et de structuration des données.
-
Support des formats standardisés: prise en charge des formats reconnus dans le cadre de la facturation électronique (Factur-X), de l’échange inter-entreprises (EDI) et des structures JSON classiques.
-
Reconnaissance optique de caractères (OCR): extraction automatisée des données depuis des images ou fichiers PDF (ex. tickets de caisse, documents scannés) via Mindee et Rossum.
-
Interopérabilité avec Axelor Open Suite: intégration native des données dans les objets métiers d’AOS tels que les factures, commandes, ou notes de frais.
-
Traitement en masse: possibilité d’ingérer plusieurs fichiers en une seule opération via une archive ZIP, pour un traitement automatisé à grande échelle.
-
Connexion à un serveur distant: récupération automatique de fichiers via le protocole SFTP, avec association possible à un traitement en masse.
-
Flexibilité et extensibilité: architecture modulaire et configurable permettant une adaptation aux spécificités de chaque organisation.
-
Partage de configurations: import/export des configurations de templates facilitant leur réutilisation et leur déploiement dans différents contextes.
Cycle de traitement et composants
Le fonctionnement du module Data Capture repose sur un cycle de traitement en quatre étapes : extraction / mappage / contrôle / génération. Ce cycle assure une intégration fluide et cohérente des données issues de fichiers formatés dans l’ERP.
- Le template : cœur du processus
Le template constitue l’élément central du module. Il rassemble l’ensemble des paramètres, règles de traitement et configurations nécessaires pour gérer un type de fichier, depuis son import jusqu’à la génération de l’objet métier dans Axelor.
Détail des étapes du cycle
-
Extraction : identification et récupération des données brutes depuis un fichier JSON, Factur-X, EDI, ou via une source OCR.
-
Mappage : association des données extraites aux champs définis dans la structure cible de l’ERP.
-
Contrôle : application de règles métier et de scripts Groovy pour valider la cohérence des données.
-
Génération : transformation des données validées en objets métiers exploitables dans AOS (factures, bons de commande, etc.).
Paramètres de capture
Les paramètres de capture définissent la configuration utilisée par un template. Ils garantissent la cohérence et la réutilisabilité des processus de traitement :
-
Un schéma de données à utiliser.
-
Des règles de contrôle à appliquer pour valider les données extraites.
-
Choix du type de génération (données extraites ou processus de rapprochement).
-
Paramètres propres à l’OCR pour le traitement de documents visuels.
Schéma et champs
Le schéma (via les objets Schema et Schema Field) définit la structure cible dans laquelle les données extraites seront injectées. Il permet une correspondance précise entre les champs du fichier source et ceux de l’ERP, assurant ainsi l’alignement des données.
Règles de traitement
Les règles de traitement sont exprimées en Groovy et couvrent différentes étapes du processus :
Règles d’extraction : personnalisent la récupération des données pertinentes.
Règles de mappage : assurent la transformation et l’alignement des données avec les objets métiers.
Règles de contrôle : valident la cohérence des données via des règles métier.
Règles de post-traitement : permettent des actions supplémentaires après l’intégration (ex. enrichissement des données, notifications, déclenchement de workflows).
Table de correspondance
La table de correspondance facilite l’harmonisation des données en associant des valeurs externes (ex. codes fournisseurs ou unités de mesure) aux références internes utilisées dans l’ERP, garantissant ainsi une homogénéité dans le traitement des informations.