Internationalization
Internationalization, often referred as i18n, is a very important feature of any business application in today’s globalized economy.
The Axelor Open Platform provides a very efficient way to make your application multilingual.
Translations
Unlike the standard Java practice to provide translations catalogs with properties files, the translations are stored in CSV files per language bases. This is because, Axelor Open Platform stores and loads translations from database to allow live update of translations by end-users.
The structure of the translation files in an axelor module looks like this:
src/main/resources/i18n/messages.csv src/main/resources/i18n/messages_en.csv src/main/resources/i18n/messages_fr.csv
The messages.csv is the template from which we have to create language specific
messages_<language>.csv files. The template should not be updated manually as
it’s automatically generated using the string extraction utility.
The following gradle task can be used to extract and update message files:
$ ./gradlew i18n [--with-context]The CSV files now has four columns:
-
key- the original string -
message- the translated string -
comment- some comments for/by language translator -
context- a list of file names with line numbers where the text can be found
The context column is populated only if --with-context option is used.
The translation messages are imported in database during the db initialization.
The corresponding database table only stores key and message.
The key is original text extracted from the java, groovy or xml files. In case of fields where title is not given, the field name is automatically converted to human-readable form.
<entity name="Contact">
...
<string name="fullName" help="true" />
...
</entity>In this case, as there is no title given, a human-readable text Full name is
generated and used as key. Also, the help="true" is used to automatically
generate key for help attribute. The format of auto generate help key is
help:<entity>.<field> so in this case a key help:Contact.fullName is
generated.
The context is a list of file name + line number where the key is found:
main/resources/domains/Contact.xml:100 main/resources/domains/Contact.xml:150 main/java/com/axelor/contact/controller/HelloController.java:57
It means the key is found in those files on the given line. This allows translators to locate the text and understand the context to provide correct translation or suggest changes in case of conflicting meanings. In that case we can choose to use some logical non-human readable keys and provide readable text from the translation.
Because of the context column begin multiline values, it’s difficult to edit the csv files in plain text editors. So always prefer editing with some spreadsheet editors (excel or libreoffice).
Strings
The string values from xml sources don’t require any special treatments but
translatable strings in you code must be wrapped with a special method I18n.get(…).
The I18n is defined under com.axelor.i18n package and provides static
methods to get translations and custom ResourceBundle which can be used with
standard java translation API.
// get the translation for the given text
I18n.get("Full name");
// get the translation for the given key
I18n.get("so.customer.title");
// get singular or plural translation based on the given number
I18n.get("{0} record selected.", "{0} records selected.", selected.size());The I18n.get only works when JPA context is started as the translation is
loaded from the database table (which is imported from the csv files during
database initialization).
So the I18n.get should not be called if the code is executed before the
JPA context is initialized (like static variables).
Value Translation
Value translation feature allows us to translate record values.
<entity name="Product">
<string name="name" translatable="true" /> (1)
...
</entity>| 1 | the field is marked as translatable |
The value translations are stored with key in value:<value> format. For example, value:Laptop or
value:Hard Disk etc.
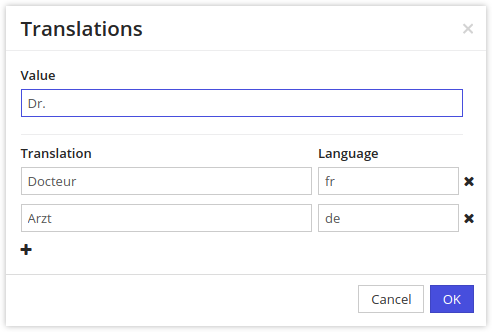
The field values can be translated by clicking on a flag icon visible on that field:
The translation dialog looks like this: